×
MZQR: An Interactive Zoo Catalog for Manila Zoo
MZQR is an application made in 2024 for a subject "Operating Systems", created to understand the architecture and nuances of different operating systems. As such, cross-platform development is the primary
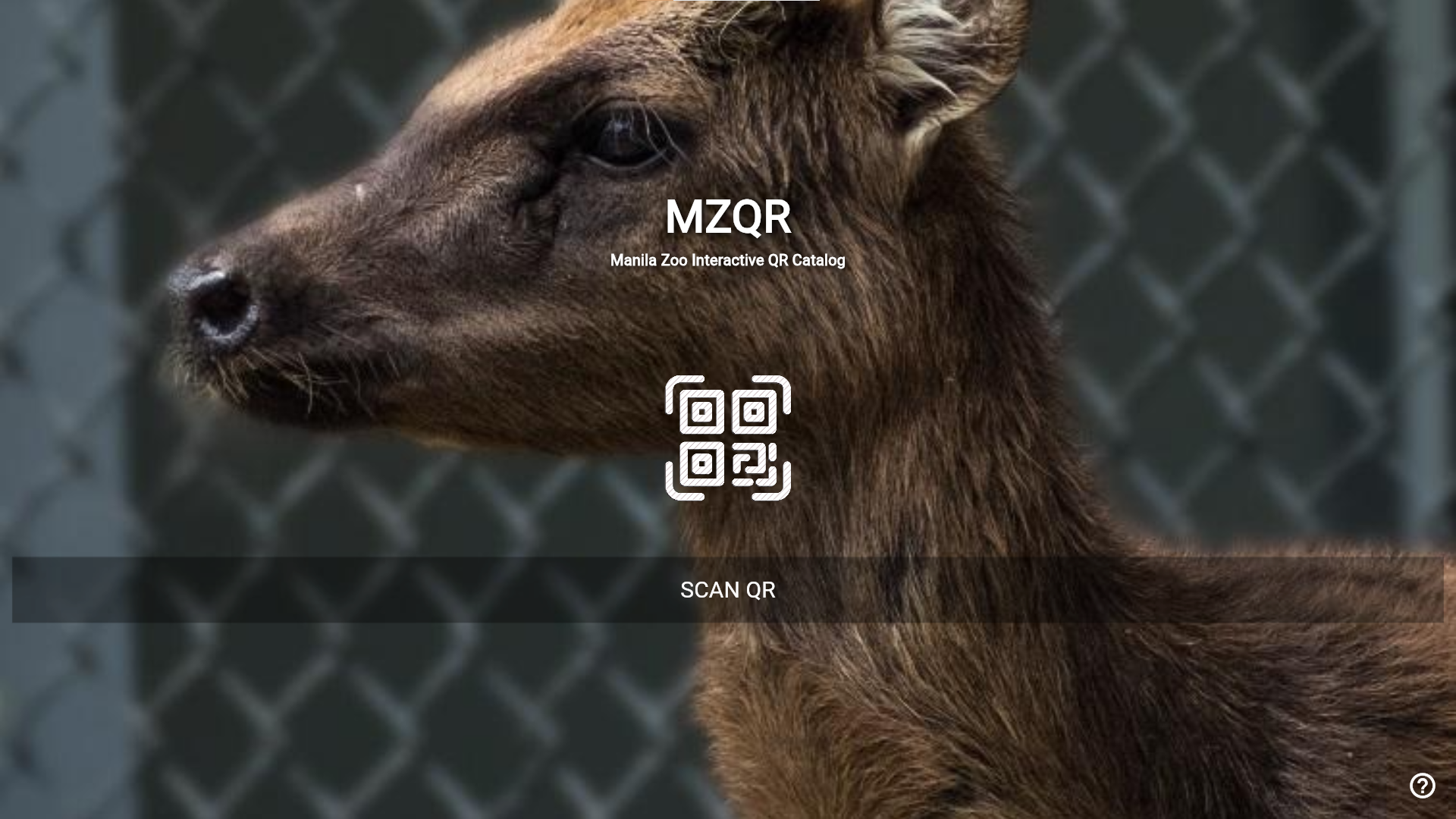
focus of this project. Made with permission from Manila Zoo's director. The application is an interactive zoo catalog for Manila Zoo, utilizing QR code technology to provide visitors with information about the animals in the zoo, reducing the need
for large and outdated signages.
The application allows zoo visitors to scan QR codes placed near animal enclosures, which then directs them to detailed information about the animal, including its species, habitat, diet, and interesting facts.
The app also includes animal information that is specific to the Manila Zoo, such as the animal's name, years it has been at the zoo, and any unique characteristics associated with it, and year of acquisition.
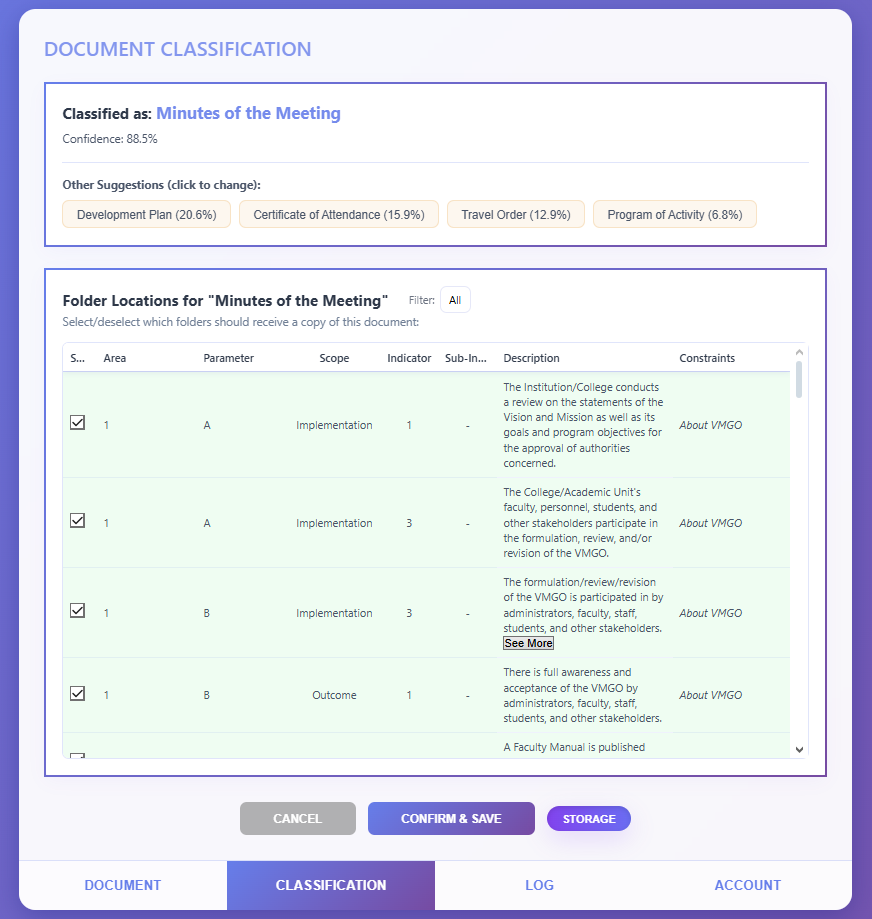
All changes are updated real-time. The administrator of the zoo, as well as the zookeepers have access to the admin side of the app, and can make changes to the details of the animals at anytime. The app also
have automated report generation on how many visitors the zoo got by tracking the number of unique device scans per day, month, and year. In the end, MZQR has been deployed to Android, iOS, and Windows devices,
as well as to a Web System.
I designed the system architecture of the app, including its functionalities and restrictions. I was also responsible for co-developing the entire frontend and backend of this project, as well as co-designing
the app layout and user experience, as well as implementing the real-time database of the app. I led the research team that gathered all the necessary information about the animals in Manila Zoo from the zookeepers,
staffs, and administrators, ensuring accuracy and relevance of the content provided in the app.
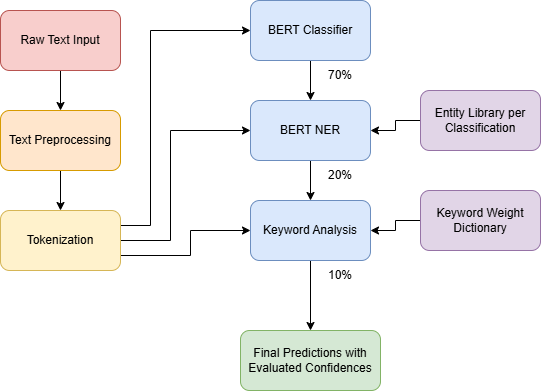
Like mentioned before, MZQR has been developed using Flutter and Dart as the programming language, allowing for a cross-platform deployment without rewriting the codebase. XCode was also used for importation of the
app to iOS platform. Firebase was used as the database management system, enabling real-time updates and easy data retrieval for animal information and visitor statistics. Along with it, Firestore was used for cloud
storage of images and other media files related to the animals, the zoo, and the application.